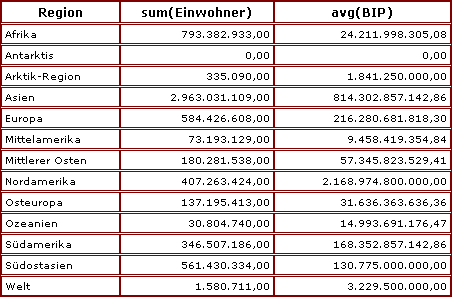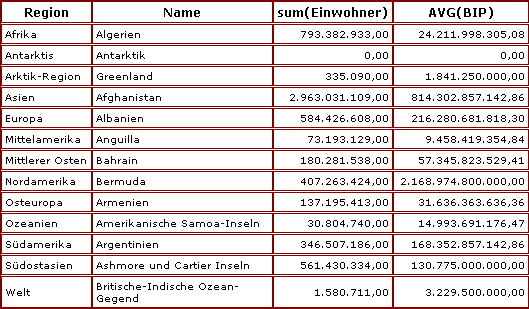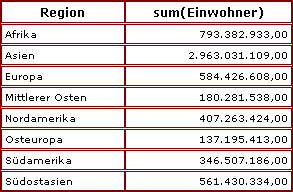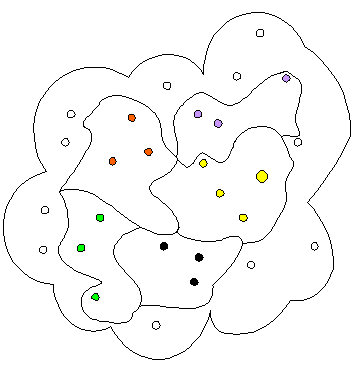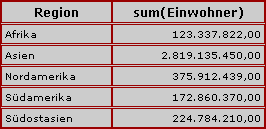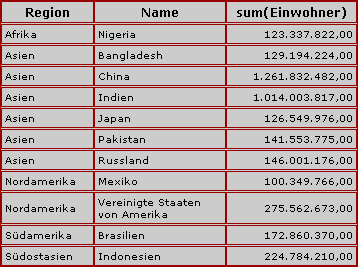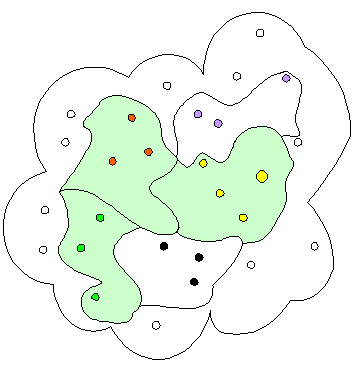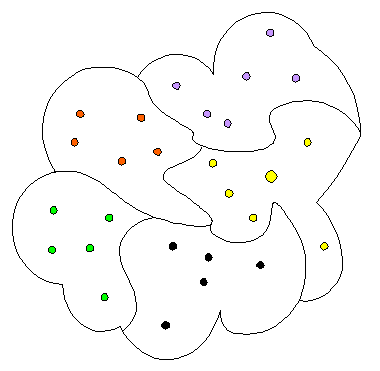
Im Bild stellt die Gesamtwolke die Menge aller Datensätze dar. Jeder Punkt symbolisiert einen Datensatz. Diese Menge ist mittels group by farbe in fünf Gruppen eingeteilt, z. B. haben wir links unten die Gruppe der "grünen" Datensätze.
Hat man die Datensätze mittels group by in Gruppen eingeteilt, so kann man nur noch Angaben über die Gruppen machen, nicht mehr über einzelne Datensätze. Man kann also Informationen über die Gruppe der gelben Datensätze ausgeben, aber keine Detailangabe über den großen gelben Datensatz.